TGTGInsighttelegram intelligenceLIVE / telegram public index
Неодамнешни објави
Неодамнешни објави
Страница 14 од 51 · 605 објави
Објавено 11 окт.
Hands-On Data Analysis with Pandas Автор: Stefanie Molin Год издания: 2019 Рецензия на книгу: Книга научит вас анализировать данные и извлекать из них ценные сведения, а также познакомит с основами машинного обучения. Плюсы: 1. Читателям предлагается использовать реальные наборы данных 2. Вы научитесь пользоваться библиотками Python для data science, такими как pandas, NumPy, matplotlib, seaborn и scikit-learn. Минусы: не замечено. #data_science#python#pandas#english Скачать книгу
401 views
Објавено 11 окт.
📕 Python. Визуализация данных. Matplotlib. Seaborn. Mayavi Автор: Абдрахманов М. И, 2020 Описание: В этой книге будут рассмотрены вопросы визуализации данных, а именно построение линейных и ступенчатых графиков, диаграмм рассеяния, столбчатых и круговых диаграмм, гистограмм и 3D графиков. Большое внимание уделено настройке внешнего вида графиков, их элементам и компоновке. • Скачать книгу из архива • Стоимость в магазине 📚Книжный клад | #Python
344 views
Hashtags
Објавено 11 окт.
🧹Как почистить данные, не удаляя лишние знаки ➡️Читать дальше @data_analysis_ml
313 views
Објавено 11 окт.
✔️Продвинутая работа с большими объемами данных Как часто вы сталкиваетесь с необходимостью выгрузить в MS Excel более миллиона строк? Все фильтры на выгрузку уже были наложены ранее, но, увы, она до сих пор «не проходит по габаритам». Перед нами встает дилемма – делить, или … воспользоваться готовыми решениями для python, не изучая python! Речь сегодня пойдет о трех библиотеках, которые позволяют писать код и при этом не писать его, а также оперировать внушительными объемами данных с минимальными знаниями английского языка или синтаксиса пресловутых «панд» (здесь и далее «панды»: pandas – open-source библиотека для python для работы с табличными данными – прим. автора). Для примера будем использовать объявления о продаже автомобилей Toyota с известного сайта. Первая библиотека, с которой хотелось бы Вас познакомить – Bamboolib. Не секрет, что панды питаются бамбуком, и, как за всякое пропитание, за него нужно платить. Да, у Bamboolib есть платная версия, в которой реализована поддержка Apache Spark, а также есть возможность использовать свои внутренние библиотеки и нет ограничения по плагинам, в остальном же достаточно бесплатной версии. ➡️Читать дальше @data_analysis_ml
314 views
Објавено 9 окт.
топ 10 вопросов по PANDAS на Stackoverflow
341 views
Објавено 9 окт.
https://deepnote.com/workspace/avi-chawla-695b-aee6f4ef-2d50-4fb6-9ef2-20ee1022995a/project/StackOverflow-Questions-d5aaa600-f9de-4918-a993-ef3283cfd6c0/%2Fnotebook.ipynb
348 views
Објавено 2 окт.
Подготовка датасета для машинного обучения: 10 базовых способов совершенствования данных У Колумбийского университета есть хорошая история о плохих данных. Проект в сфере здравоохранения был нацелен на снижение затрат на лечение пациентов с пневмонией. В нём использовалось машинное обучение (machine learning, ML) для автоматической сортировки записей пациентов, чтобы выбрать тех, у кого опасность смертельного исхода минимальна (они могут принимать антибиотики дома), и тех, у кого опасность смертельного исхода высока (их нужно лечить в больнице). Команда разработчиков использовала исторические данные из клиник, а алгоритм был точным. Читать...
463 views
Објавено 2 окт.
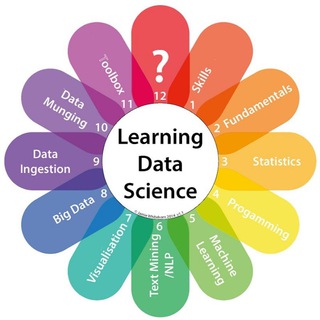
— views
Објавено 2 окт.
#книга#ru
310 views
Објавено 1 окт.
15 нейросетей в один Telegram-бот: история успеха и реализация помощника для создателей контента. https://habr.com/ru/post/690922/
304 views
Објавено 29 сеп.
Даункастинг в Pandas для эффективного использования памяти. https://itnext.io/storing-pandas-data-frames-efficiently-in-python-cff669953485
329 views
Објавено 29 сеп.
✔️PANDAS VS SQL для работы с данными. Еще порядка 10 лет назад для работы по исследованию данных было достаточно SQL как инструмента для выборки данных и формирования отчетов по ним. Но время не стоит на месте, и примерно в 2012 году стала стремительно набирать популярность Python-библиотека Pandas. И вот сегодня уже сложно представить работу Data Scientist’а без данного модуля. Не буду подробно углубляться в то, что предоставляют из себя оба инструмента ввиду их популярности среди аналитиков и исследователей данных, но небольшую справку все-таки оставим: Итак, SQL (язык структурированных запросов — от англ. Structed Query Language) — это декларативный язык программирования, применяемый для получения и обработки данных с помощью создания запросов внешне похожих по синтаксису на предложения, написанные на английском языке. Pandas — это модуль для обработки и анализа данных в табличном формате и формате временн́ых рядов на языке Python. Библиотека работает поверх математического модуля более низкого уровня NumPy. Название модуля происходит от эконометрического понятия «панельные данные» (или как его еще называют «лонгитюдные данные» — это данные, которые состоят из повторяющихся наблюдений одних и тех же выбранных единиц, при этом наблюдения производятся в последовательные периоды времени). ➡️Читать дальше @data_analysis_ml
315 views